起因,突发奇想做 网页导航
前段时间突发奇想,想在自己的博客页面上搞一个静态的网页导航,实现一些常用网页的跳转,或者是一些软件的下载地址合集。
本来是一件很简单的事情,而且有很多方法可以实现。所以我找了个最简单的方法——用 Markdown 直接转 HTML。然后就做出了这个 软件下载页面,非常简陋,但是功能上已经实现了我的要求。
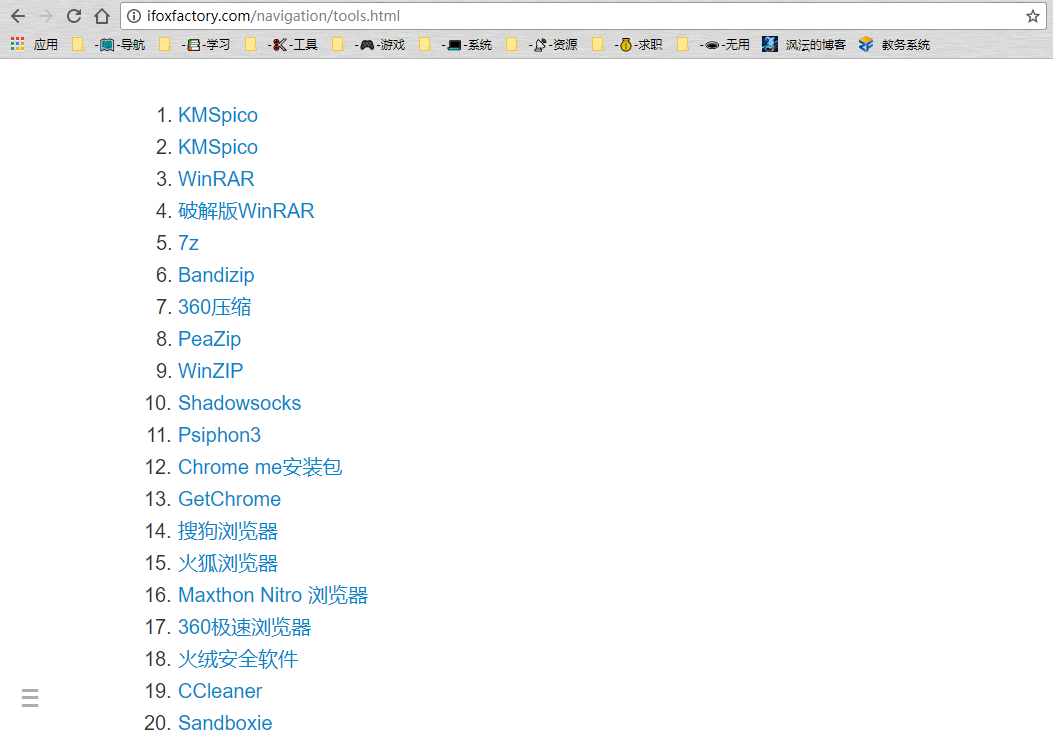
这时候总会想一些骚操作,我觉得这个页面过于简单,简单到自己都不愿意打开它。
如果用 BootStrap 这种框架好像有点费事,并不想在 Github Pages 上放太多多余的东西,毕竟以博客为主,以后租个服务器玩这些比较靠谱。
这时想到正好手头有一个叫 DropIt 的软件,可以自动生成本地文件列表。我就直接制作了一份。
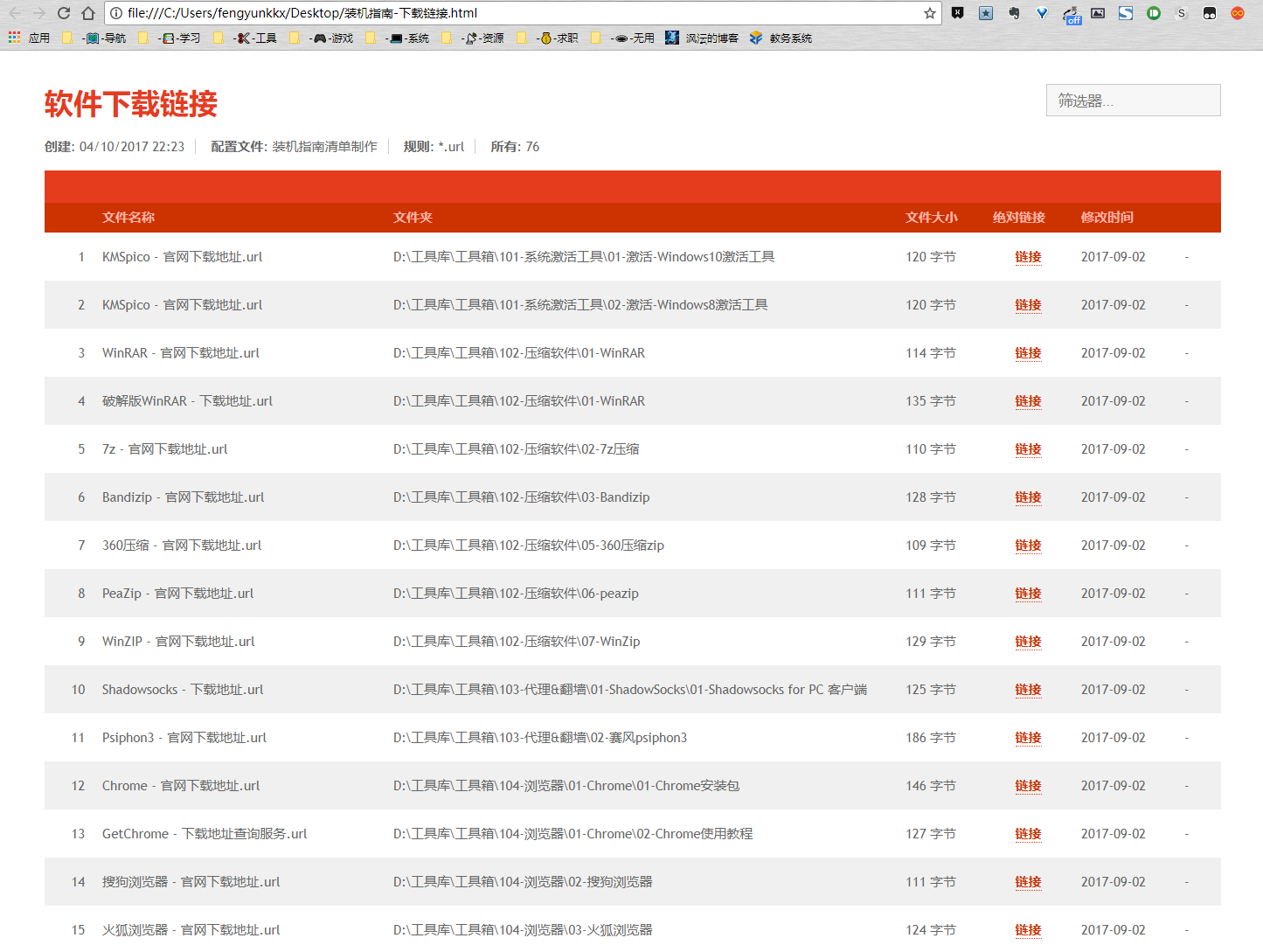
然后发现这个链接只能连接到本地文件,并不是导航到下载地址。于是手动改了一下 HTML,这时候我才发现替换起来好像有点麻烦。
Markdown 转 HTML 生成的部分是用 <li> 标签实现的列表。

但是在 DropIt 中自动生成的是表格。

我把表格删到只剩下一列,将所有的<li>替换为<td>,基本实现了效果。但是只有一列看上去太窄了,筛选器和左上角的文字会重叠。我又加了一行用来显示网址。于是变成了两列,我想把一列变成「软件名称」,一列变成带链接的「下载地址」,就像下图这样。
搞事,需要正则表达式替换
由于这个操作里有着不确定的「网址」和「软件名」,常规替换无法批量执行。然后我正好发现 Atom 支持正则表达式的替换,那就顺便学习一下正则表达式吧。
学习正则表达式基本用法
经过一番爬帖,掌握了一些特别字符的用法——
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。 |
| ( ) | 标记一个子表达式的开始和结束位置。 |
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| . | 匹配除换行符 \n 之外的任何单字符。 |
| [ | 标记一个中括号表达式的开始。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
| \ | 转义字符。 |
| ^ | 匹配输入字符串的开始位置。 |
| { | 标记限定符表达式的开始。 |
| | | 指明两项之间的一个选择。 |
这里还需要用到 懒惰 匹配,懒惰匹配的用法如下——
| 懒惰 | 描述 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
处理第一行代码
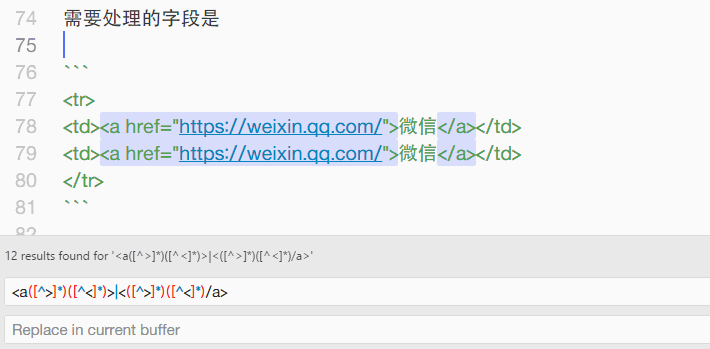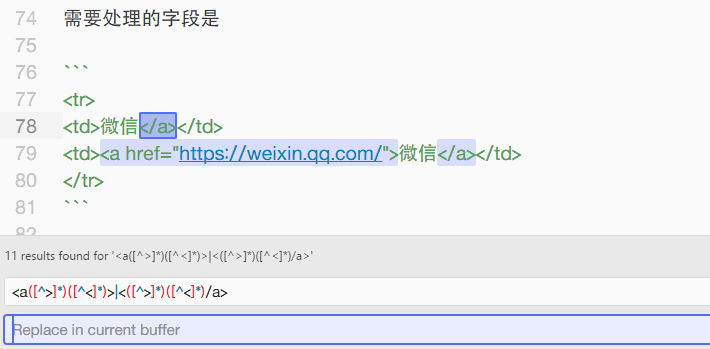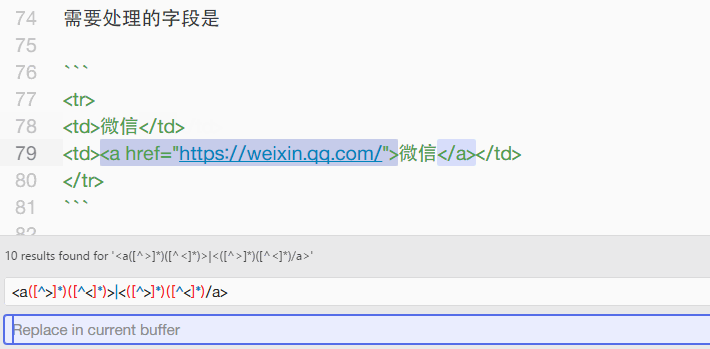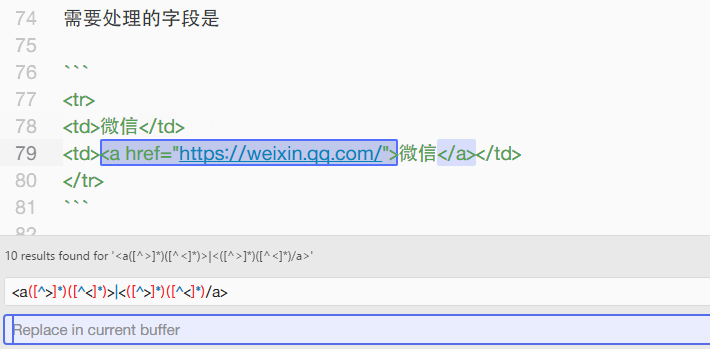
需要处理的字段是
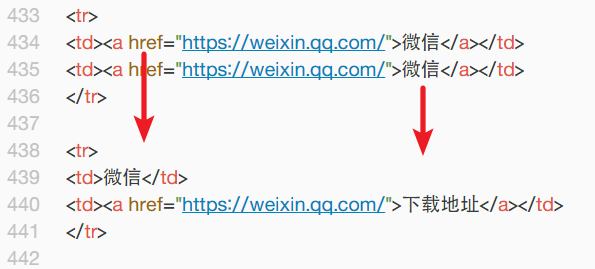
<tr>
<td><a href="https://weixin.qq.com/">微信</a></td>
<td><a href="https://weixin.qq.com/">微信</a></td>
</tr>
「以 https 开头以 “ 结尾之间的字符片段」,可以用 (https)(.*?)(?=") 这个正则表达式来查找 https://weixin.qq.com/ 这个链接。其中的 .*? 为懒惰匹配。
根据我的需要,我想把 <a href="https://weixin.qq.com/">微信</a> 这部分内容替换为 微信 ,所以理所当然的搜索了 (?<=<a>)(.*?)(?=</a>),结果发现是无效的表达式。我意识到是尖括号没有进行转义。
继续爬资料,发现应该使用 <([^>]*)([^<]*)> 来匹配尖括号内的内容。稍加修改,改为 <a([^>]*)([^<]*)>|<([^>]*)([^<]*)/a> ,就可以将 <a> 和 </a> 标签完整地清除了。
处理第二行代码
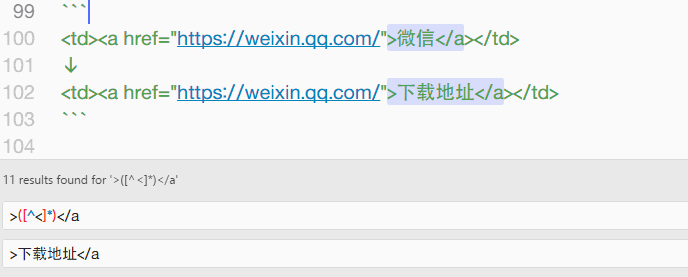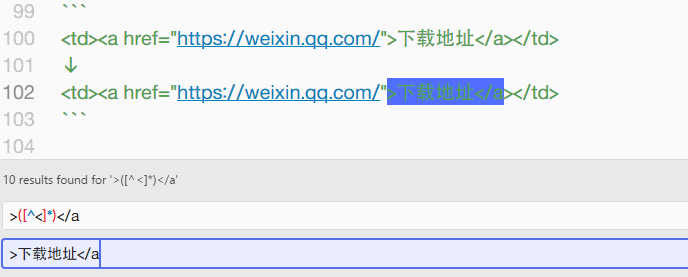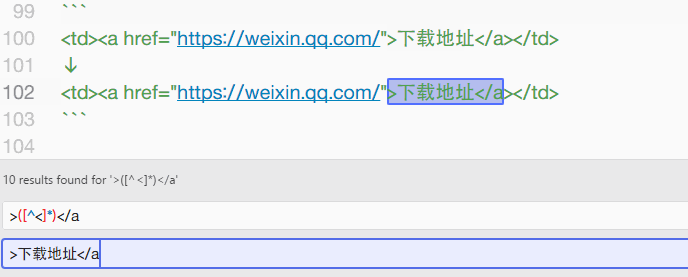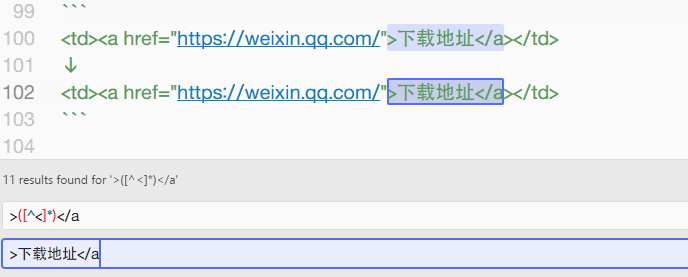
然后对第二行进行操作,需要将 微信 二字更换为前面的链接。稍加思索,只需要把> </a> 之间的字符替换为「下载地址」即可。
<td><a href="https://weixin.qq.com/">下载地址</a></td>
↓
<td><a href="https://weixin.qq.com/">下载地址</a></td>
所以搜索字符:>([^<]*)</a,替换字符:>下载地址</a,即可达成目标。
同理,当 Chrome 的收藏夹导出后,会自动包含 ADD_DATE= 和 ICON= 的字符串信息,将 ADD([^>]*)([^<]*)> 替换为 > 即可完成所有的替换工作。

完结,还有一些想说的
当然,真正的探索过程没有文中那么一帆风顺,我花了大概四个小时的时间才把正则表达式的操作学习完,并在多次之后将这个步骤完成。包括尝试了不少奇怪的操作,也贴上来博君一笑。
<a href="([^:]+:\s*)([a-zA-Z]+)">([^:]+:\s*)([a-zA-Z]+)</a>
<a href="\2">\1\2</a>
<"\2"><title>\1\2</title>
尽管这次探索的时间成本远远超出了手动修改的时间,但是这对我而言是一次掌握新知识,非常有价值。
参考资料:
正则表达式:Notepad++查找两段特殊字符之间文字并在该目标字符后面添加字符
Java进阶——使用正则表达式检索、替换String中的特定字符和关于正则表达式的一切